|
|
Zengyi Qinqinzy [at] alum.mit.edu Twitter | LinkedIn |
Researcher. All in
Entrepreneur. Build AI agent platform with 6M users, 265K agents created, 55M audience reached.
Founded OpenAGI Labs and delivered the state-of-the-art Computer Use models, used by 2000+ developers.
Have
I first proved you can do pre-training from scratch and outperform big labs (Meta, Google) despite having 1000 times fewer resource. That was 6-month ealier than the DeepSeek moment. Almost nobody believed before we actually did it.
Endorsed by MIT official social media for multiple times [1] [2] [3].
Technical blog
MIT CSAIL posts
Comments from the field (1 2 3)
The breakthrough represented by JetMoE-8B signals a significant democratization of AI technology (1)
Technical blog
Trended 1st on Github
Now
Covered by VentureBeat, HyScaler and other medias
AI Voice Cloning Redefined: OpenVoice Unveils Revolutionary Open-Source Technology (1)
|
Introducing Lux, the State-of-the-Art Computer-Use Model
Lux can operate the computer like a human, seeing the screen and taking actions across real desktop and web workflows. It outperforms current frontier models while being much more efficient. |
|
OSGym: Scalable OS Infra for Computer Use Agents
OSGym parallelizes thousands of OS replicas at academic cost, enabling large-scale data generation, customization, and end-to-end pipelines for RL across diverse real-world tasks to train computer use agents. |
|
OpenVoice: Versatile Instant Voice Cloning Instantly clone any voice to generate speech in various styles and languages. |
|
MeloTTS: A high-quality multi-lingual multi-accent text-to-speech library High-quality multi-lingual text-to-speech library that supports English (US, BR, AU, INDIAN), Spanish, French, Chinese, Japanese and Korean
Star |
|
JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars JetMoE is pre-trained and post-trained from scratch with less than 0.1M USD cost but outperforms LLaMA2-7B. It democratized high-performance LLM pre-training and post-training with remarkable cost-efficiency. |
|
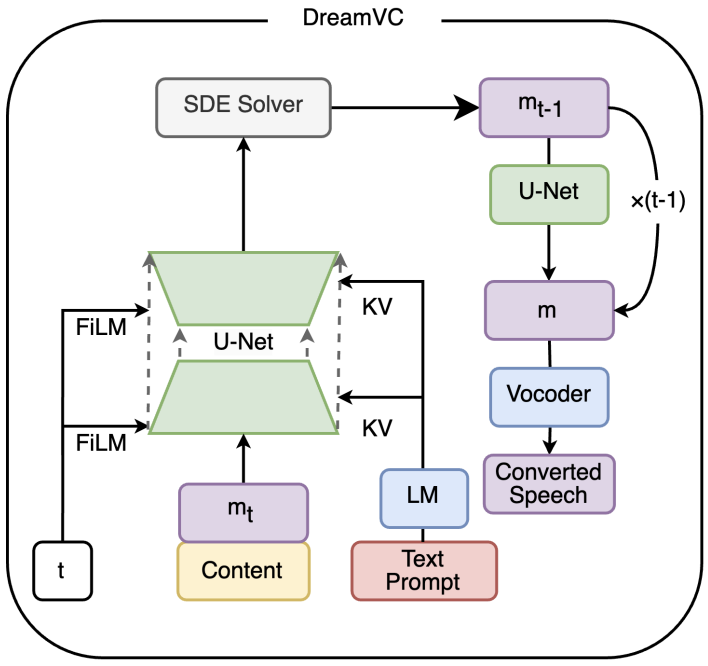
DreamVoice: Text-Guided Voice Conversion Convert a voice into any voice based on the input text prompt. |
|
MonoGRNet: A General Framework for Monocular 3D Object Detection A general monocular 3D object detection framework that flexibly adapts to both fully and weakly supervised learning, which alleviates the need of extensive 3D labels and only requires ground truth 2D bounding boxes during training. |
|
Weakly Supervised 3D Object Detection from Point Clouds A state-of-the-art framework for weakly supervised 3D object detection from point clouds without using any ground truth 3D bounding box for training. The core of our method is the unsupervised 3D object proposal module and the cross-modal knowledge distillation strategy. |
|
Triangulation Learning Network: from Monocular to Stereo 3D Object Detection This is a pioneering work on stereo image based 3D object detection without calculating the pixel-level depth maps. We proposed a triangulation learning method to learn the object-level stereo geometric correspondence for 3D object detection. |
|
MonoGRNet: A Geometric Reasoning Network for Monocular 3D Object Localization A state-of-the-art monocular 3D object detection approach based on geometric reasoning. We proposed to decompose the whole task into four progressive sub-tasks that significantly facilitates the monocular 3D object detection. |
|
SABLAS: Learning Safe Control for Black-Box Dynamical Systems Learning control barrier functions (CBFs) for safe control of black-box systems. CBFs are a powerful tool to provide safety guarantee, but before this work, they cannot be directly applied to black box systems where their models are unavailable. |
|
|
KETO: Learning Keypoint Representations for Tool Manipulation KETO is a framework for robots to manipulate unseen objects as tools to complete diverse tasks. We proposed a method to learn the keypoint representations of objects, which simplify the manipulation task and improve the generality to novel objects. |
|
Learning Safe Multi-agent Control with Decentralized Neural Barrier Certificates We study the multi-agent safe control problem where agents should avoid any collision while reaching their goals. Our method can scale up to an arbitrarily large number of agents (e.g., >1000 in our experiments) and achieve a 99-100% safety rate. |
|
Reactive and Safe Road User Simulations using Neural Barrier Certificate Reactive and safe agent modelings are important for nowadays traffic simulator designs and safe planning applications. We propose a control barrier function-based method to simulate traffic agents that behave like humans or human controlled vehicles, which react to other road participants. |
|
|
Density Constrained Reinforcement Learning We study constrained reinforcement learning (CRL) from a novel perspective by setting constraints directly on state density functions, rather than the value functions considered by previous work. State density has a clear physical and mathematical interpretation, and is able to express a wide variety of constraints such as resource limits and safety requirements. |
|
Safe Nonlinear Control Using Robust Neural Lyapunov-Barrier Functions Safety and stability are common requirements for robotic control systems. We propose a robust feedback method based on robust control Lyapunov barrier functions that generalize despite model uncertainty, and with safety and stability guarantee. |
|
Controller synthesis for linear system with reach-avoid specifications We address the problem of synthesizing provably correct controllers for linear systems with reach-avoid specifications. Our solution decomposes the overall synthesis problem into two smaller and more tractable problems, achieving a 2-150 times speedup compared with the previous techniques. |
|
Learning fine-grained estimation of physiological states from coarse-grained labels by distribution restoration Our method allows machine learning algorithms to perform fine-grained estimation of physiological states (e.g., sleep depth) even if the training labels are coarse-grained. |
|
sEMG based Tremor Severity Evaluation for Parkinson's Disease using a Light-weight CNN A machine learning framework to assist the diagnosis of Parkinson's Disease by assessing the pathological tremor. We proposed a light-weight convolutional neural network and a similarity learning strategy to handle the scarcity of medical data. |

















{kind=link}
{kind=link}